
Recientemente he empezado esta serie de post donde iré desgranando mi proyecto final de Máster en Inteligencia Artificial relacionado con el mundo SIG. Si quieres ver un resumen de todo el proyecto te remito al post anterior.
En este post voy a centrarme en explicar el proyecto del Atlas de Expansión Urbana que utilizo como punto de partida, un pequeño resumen de la extracción de datos que requería, la metodología usada, en qué punto una solución con IA podría utilizarse y que sirva un poco como ejemplo de cómo poder ir desgranando un proyecto hasta hacerlo viable.
El proyecto de «Atlas of Urban Expansion» fue un proyecto muy interesante en el que participé elaborado con motivo del congreso Habitat III sobre la monitorización del crecimiento de las ciudades. El aumento descontrolado de su tamaño y la tipología de esta expansión puede causar un mal crecimiento que afecte directamente a la calidad de vida de sus ciudadanos. Esta mala planificación puede causar carencia de infraestructuras básicas, aumento de costes de mantenimiento, desigualdad social, movilidad, barrios marginales (slums).. El objetivo es demostrar de forma empírica, con datos, este crecimiento y todos sus problemas asociados.
Ejemplos de problemas urbanísticos que pueden acarrear desde problemas de servicios a problemas de transporte:



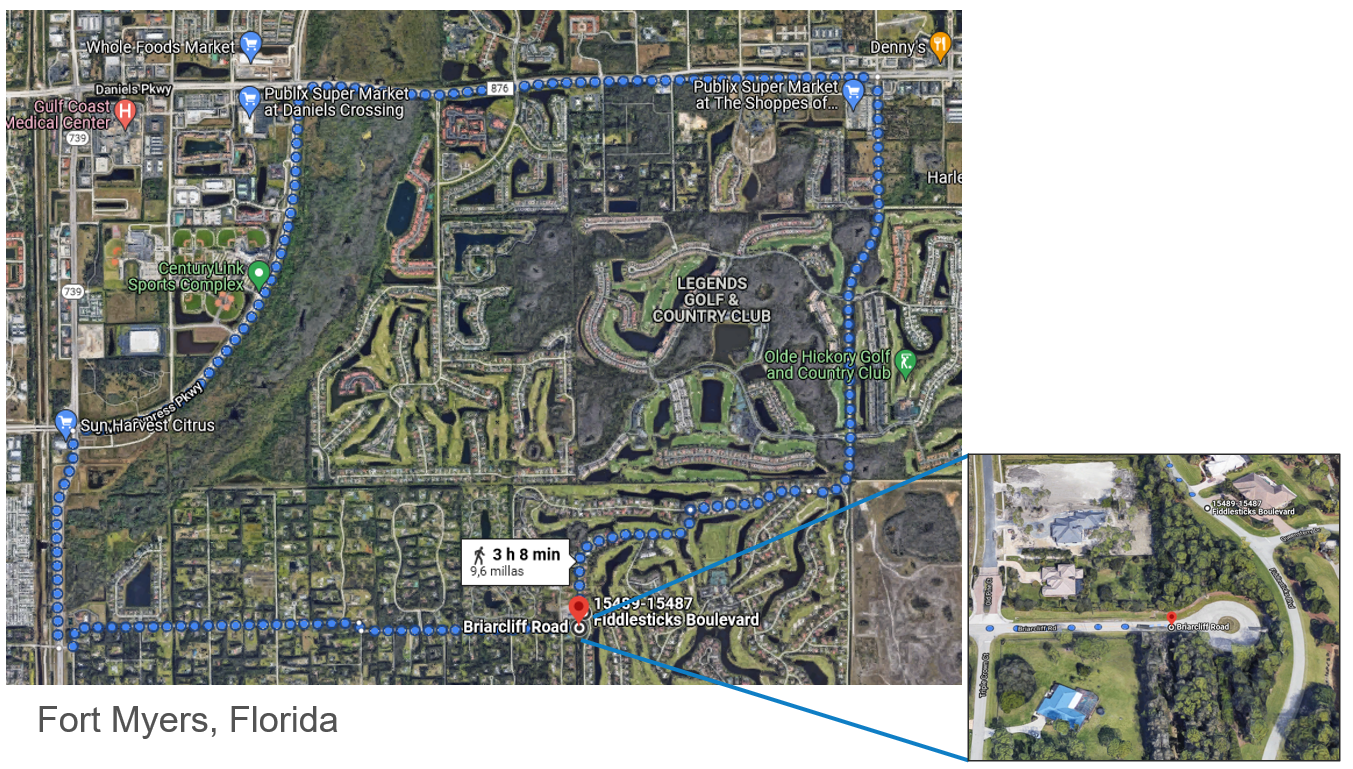
Aquí podemos ver un claro ejemplo de problemas asociados a la trama urbana sacado del foro de Reddit Suburbanhell. Se puede ver que para visitar a un vecino la ruta a seguir es de más de 3 horas caminando. Esto ocurre al tratarse de proyectos urbanísticos independientes entre sí con una mala comunicación con la trama urbana.
Me remito a diferentes fuentes para los que estéis más interesados en saber todo el alcance de este proyecto: Ponencia de Manuel Madrid, resumen del Atlas en el Lincon Institute. Todo el estudio se puede descargar de forma gratuita, publicado en dos libros: Volumen 1:Áreas y densidades , Volumen 2:Parcelas y carreteras. La web oficial parece que se encuentra actualmente caída.
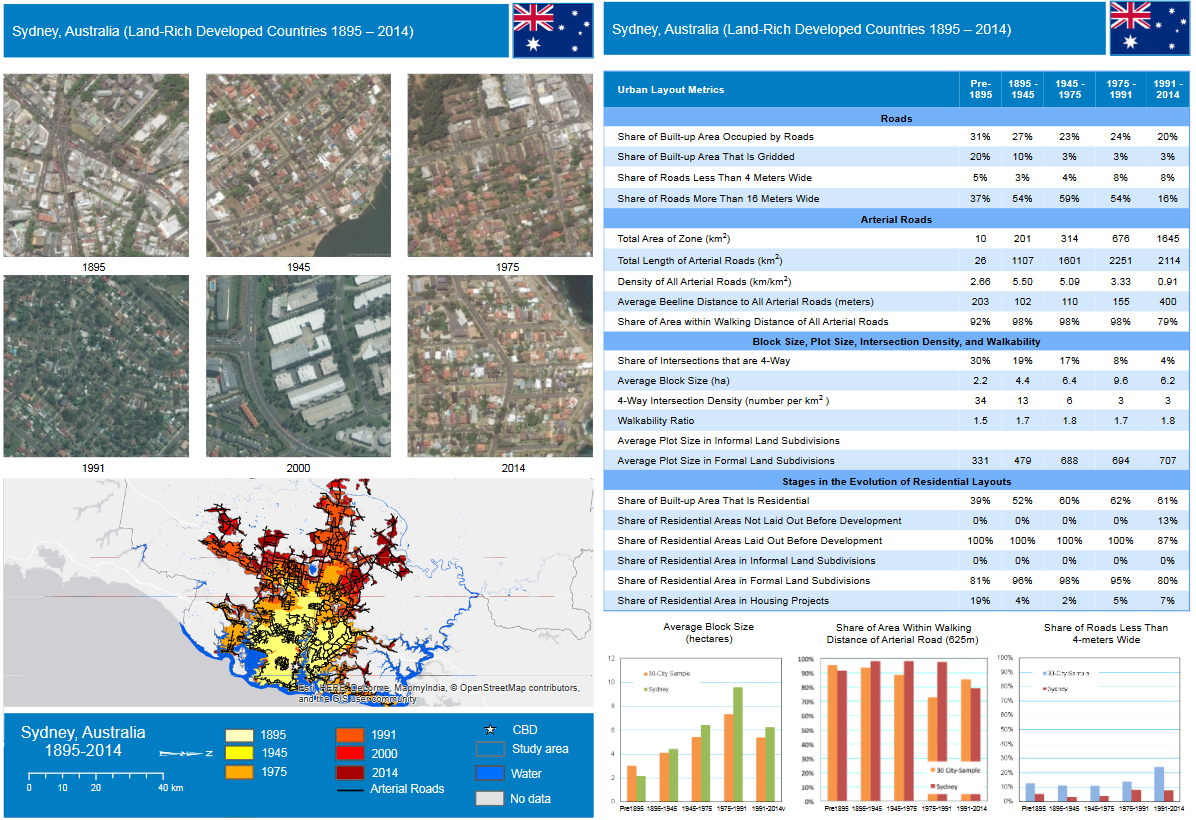
En este estudio de ámbito mundial, se pedía un análisis de 200 ciudades esparcidas por todo el globo, de diferentes tamaños, tipos, culturas.. Necesitaba de datos urbanos que le permitiesen calcular una serie de métricas. Se buscaba una forma homogenizada de obtener datos en crudo sobre estas ciudades para que luego las métricas que se calculaban con ellos pudieran ser comparables entre todas las ciudades del estudio.
Para tener una idea de qué tipos de métricas estoy hablando doy un par de ejemplos. Una métrica importante era la proporción entre espacio construido y espacio dedicado a calle. Otra era el número de intersecciones entre calles por área de estudio y la calidad de ellas. Por ejemplo, en zonas formales existían gran cantidad de intersecciones lo que facilitan el tránsito, y estás intersecciones eran de 4 ejes, esto lo diferencia de zonas atomísticas donde, pese a tener un mayor número de intersecciones de forma general, abundan las intersecciones de 3 ejes.
En el momento del proyecto no se consiguió obtener ninguna fuente de datos que pudiera ser de utilidad para el estudio. Para el cálculo de estas métricas es necesario datos en formato vectorial. La más cercana a ello era, obviamente, OpenStreetMap. El problema es que no podíamos tener la seguridad de que cubría de forma completa todas las zonas de estudio. Por ejemplo, la digitalización en los centros de ciudades es muy completa pero en las afueras no. Lo mismo para algunas ciudades de menor tamaño, con un urbanismo más informal, en zonas en vías de desarrollo, etc. Además, algunos requisitos sobre lo que son parcelas, lo que son ejes de calle (algunas son digitalizadas por carriles en OSM), mediciones de ancho de calles, etc no se cumplían o requerían de un procesamiento de los datos muy alto.
Ya os adelanto que el ejemplo de IA que voy a contar no soluciona ni de cerca todos los requisitos que se pedían, pero sí intentaré dar ideas para ello.
Así que se optó por la otra solución, utilizar imágenes satelitales para la extracción de datos, y ya estamos hablando de trabajo manual de digitalización. A cada digitalizar se le asignaban una serie de círculos muestrales de los que tenía que dibujar las parcelas, dividirlas si tenían diferentes tipologías, cada una etiquetada y dibujar los ejes de calles. Eso, como mínimo para cada círculo. El estudio requería de otros datos como digitalización de vías principales, anchura de calles que se hacían de diferente forma, también manual.
La información a extraer de estos datos era mucha y diversa: tamaño de parcelas, densidad de construcciones, longitud de ejes de calle.. Todas estas son muy matemáticas, con una buena digitalización y ciertos procesos se podrían calcular. En cambio, la clasificación de tipologías urbanas, es otro cantar.

Las diferentes tipologías dependen del uso, ocupación, tipo de construcción, distribución, tamaño.. que tienen en su interior las construcciones de las parcelas, la propia parcela en sí o también sus colindantes, incluso pudiendo ser mixto su uso dentro de ellas. Importante todo esto porque lo analizaremos en la problemática de esta solución. Y claro, todo trabajo manual de los digitalizadores, no había forma alguna de automatizar esto.
Las tipologías son las siguientes:
- Espacio abierto (0). Incluye parcelas no edificadas, jardines, campos de cultivo, plazas, etc. Engloba parcelas que no están edificadas pero que podrían algunas potencialmente cambiar de uso. También zonas verdes, muy importantes.
- No residencial (1). Incluye desde parcelas de uso industrial a edificios gubernamentales, religiosos, hospitales, colegios, etc.
- Atomístico (2). Zonas residenciales con una distribución de calles que se correspondería a una falta de planificación urbana.
- Informal (3). Zonas residenciales con planificación urbana pero con carencia de servicios asociados como iluminación, presencia de aceras o pavimento.
- Formal (4). Zonas residenciales con planificación urbana completamente ejecutada.
- Proyecto urbanístico (5). Zonas residenciales con una planificación propia y excluidas de la trama urbana en la que se encuentran. Se caracterizan por ser edificios normalmente muy similares que tienen una configuración de calles propias que facilita el desplazamiento entre ellos pero no con la trama urbana de la ciudad.
En la imagen se pueden ver las tipologías base.

La imagen correspondiente a la tipología Informal es de la ciudad de Guanajato, México. En la siguiente imagen se puede ver a pie de calle como sería y podemos comprobar a qué nos referimos con lo de falta de servicios.

Se pueden ver claramente las diferencias con una zona formal de la ciudad de Valencia a nivel de calle. Sin embargo, a veces, estas diferencias no están tan claras a la hora de la digitalización con imágenes aéreas.

La tipología atomística, por ejemplo, en ciudades europeas se corresponde principalmente con sus cascos históricos. En el resto, suelen estar directamente relacionadas con ciudades sin planificación o con barrios marginales también llamados slums. Muy importante el estudio de este tipo de barrios y su crecimiento.

Siempre hay un pero, como ya dije en el anterior post, la realidad es compleja, y en un ámbito mundial y tan variado siempre existen casos que se encuentran en la frontera entre dos tipologías. La confusión es tanta que hasta según el día que tenga un digitalizador puede etiquetarla de formas diferentes. Hay veces que zonas formales parecen muy atomísticas, y viceversa. Esto era un error que se tenía en cuenta y lo introduzco ya porque también será importante en los resultados de mi proyecto.
Todo esto es mucha información que obtener de una ciudad. Digitalizar ciudades enteras según estos criterios comentados de forma manual en megaciudades como Tokyo, Nueva York o Ciudad de México haría del proyecto algo totalmente inviable en tiempo y recursos.
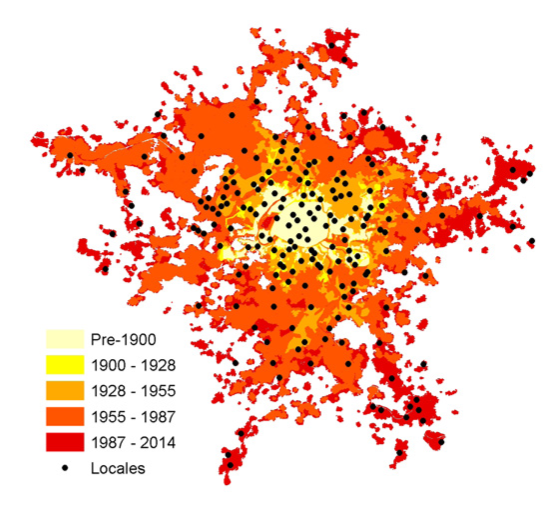
Para ello se ideó un estudio mediante círculos muestrales que seguían una distribución semialeatoria. La digitalización se debía de continuar hasta que unas variables estadísticas para esa zona basadas en las medidas comentadas se estabilizaran: para ciudades homogéneas se hacían menos círculos, para las heterogéneas muchos. Hablamos de 200 ciudades, con zonas de expansión de diferentes épocas, empezamos a hacernos una idea de cuanto trabajo manual hay..

Con esto nos hacemos a la idea de los problemas que tenía este estudio:
- Mucho trabajo manual. Obligado si queremos muestras bajo los mismos criterios con datos como la tipología que no eran automatizables, ni su extracción ni su etiquetado.
- Métricas numéricas para una ciudad. Potencialmente podríamos estar saltándonos zonas importantes.
- Basados en círculos muestrales. No podríamos hacer análisis de zonas pequeñas de una ciudad o visualizarlas en un mapa, ya que los valores que obtenemos no son continuos en todo el terreno, recordemos, solo tenemos digitalizadas las muestras.
En este proyecto me centro en la automatización del apartado de clasificación de tramas urbanas. El etiquetado considero que es la parte más subjetiva y complicada del estudio en comparación con el resto de métricas que dependen más de la digitalización.

Y ya voy adelantando, o doy ideas para otros estudios que puedan intentar esto, en mi proyecto no he abordado lo que sería la extracción de parcelas de una imagen satelital, la extracción de ejes, automatización de medidas, etc. Para mi proyecto asumí que tenía unas parcelas vectoriales digitalizadas y que esas son las que se debían de etiquetar. Destaco lo de en «mi proyecto» porque en esta serie de post me gustaría ampliar las soluciones aportadas e intentar aproximaciones nuevas.

Deja un comentario